Similarly to aspect-oriented programming, PDI distinguishes between core concerns and cross-cutting concerns.
Core concerns are the aspects of the code that fulfill its main goal. We consider as core concerns of a simulation code the aspects handled in the main loop that generate elements needed as input of the next iteration of the loop.
Cross-cutting concerns are the aspect of the code that are not core concerns. We consider as cross-cutting concerns of a simulation code:
the aspects handled before the simulation main loop such as parameters reading, data initialization, etc, the aspects handled after the simulation main loop, such as result post-processing, storage to disk, visualization, etc, the aspects handled during the simulation main loop, but whose execution is not required for the next iteration of the loop, such as fault tolerance, logging, etc. The simulation could run with none of the cross-cutting concerns implemented (even if this would be completely useless with no result ever saved). The deactivation of a core concern on the other hand would lead to a failure of the simulation.
PDI supports calling libraries from the specification tree instead of from the code. This is well suited for cross-cutting concerns but means that the code has no control over what and how these aspects are handled which does not fit the needs of core concerns.
PDI offers to exchange data between the application code and various external data handlers, such as for example the file-system for I/O or another code for code-coupling.
Before using PDI, it is however a good idea to understand the three core concepts that make this possible.
Each data exchange is a two-step process. The PDI-enabled application makes its data available through the data store. The event subsystem then notifies interested external data handlers about this change in the store. Once notified, each data handler (implemented as a plugin) can look in the store and use the data accessible from there.
The orchestration of these exchanges, the description of what data can be put in the store, what each handler should do with it, etc. is described in the specification tree.
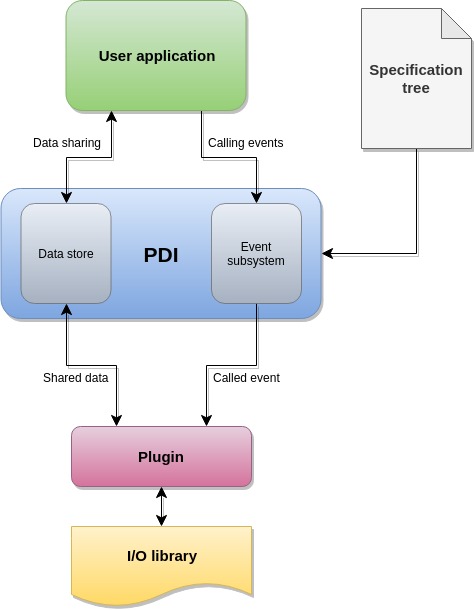
The data store is the mechanism provided by PDI to handle data transfer between the application code and external data handlers. Data transfer is the action of making data available to another part of the code. For example, in a function call the list of parameters determines data transfer.
PDI data store is somewhat similar to a file-system or a document store with some specific properties:
This approach makes it possible to exchange data between very weakly coupled code modules. Each module can add or access objects in the store and does not need to know which other module created it or how.
In summary, the store hold a set of object references, each identified by a name and that contains:
While the data store handles data transfer between the application code and external data handlers, the event subsystem handles control transfer. Control transfer is the action of passing the CPU control to another part of the code. For example, calling a function is a way to transfer control, creating a thread is another way.
The event subsystem makes it possible to observe the store and to be notified when it is accessed; thus complementing the store with a way for data handler to implement their expected behavior. Notifications are emitted when:
To ensure minimal overhead, the PDI event subsystem is synchronous by default (like a function call). Plugins can implement other behaviors on top of that. For example, a plugin could create a thread for asynchronous execution.
This approach makes it possible to exchange data between very weakly coupled code modules. Each module can execute specific code when the required data becomes available and does not need to know which other module created it or how.
The combination of the data transfer provided by the data store and the control transfer provided by the event subsystem offers the basis for weak coupling of multiple independent modules. The specification tree builds on this basis and orchestrates the interaction between the multiple modules used in an execution.
The specification tree is specified in a file written in the YAML format and provided to PDI at initialization. This makes it possible to change the list of modules to load and their interactions without having to recompile any code.
The specification tree structure is described in details in its reference documentation. It contains two main subparts:
The data types description defines the type of data expected in the store. This is most useful for non-reflexive statically typed languages (C, C++, Fortran) for which this information can not be automatically extracted at execution. The types can be expressed in function of the value of other data through $-expressions. For example, a given object might be described as an array of N doubles where N is an integer available elsewhere in the store.
The plugin list configuration defines the list of plugins to load and a configuration for each of them. Each plugin can accept a different way of specifying the configuration, but in any case, this is where the orchestration of interactions is specified. The user-code plugin is somewhat specific in that instead of providing a service itself, it enables the application to react to events and implement specific code handle data from the store.
To summarize, interactions between weakly coupled modules in PDI go through the data store that acts somewhat like a file-system. One can share data buffers in this store to make them available to other modules. When a buffer becomes available in the store, the event subsystem notifies interested modules so that they can use the data. The plugins loaded and configured through the specification tree offer various reusable services through that mechanism such as data write to disk, fault tolerance, code coupling, etc.